Background
I was recently working on a problem that involved detecting anomalies in VPC flow logs. VPC flow logs are the event logs of communication happening between two instances or more specifically between two IP addresses in a virtual private cloud and capture different aspects of communication like time, duration, bytes transferred, packets transferred, Protocol used, Port used, and many more. For any cloud-native organization, the data generated by VPC logs can be too much, in my case I was getting ~12–15 Billion records per hour which is a very high frequency (queries per second i.e. QPS). A large volume and high data velocity add complexity to the problem to be solved. The task here is to detect anomalies in the data based on specific attributes of communication. These anomalies will help in finding any vulnerability in the cloud infra and therefore securing the infra of the organization. These identified anomalies will be then verified by the incidence response team for false positive alerts or genuine threats.
Problem Description
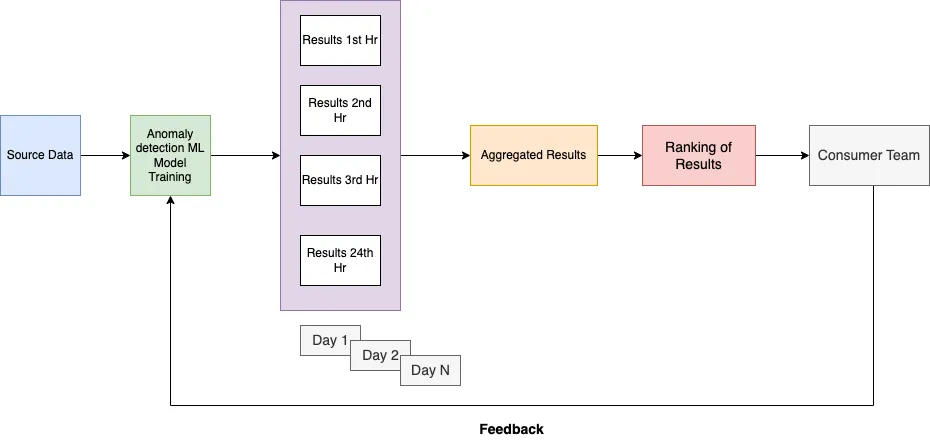
ML model is trained with the incoming data every hour and it detects a fraction of anomalies in these logs and writes these to the table. Due to the large volume of the data, a very small fraction of anomalies generated per hour can be too much for the consumer team to investigate. Every day these anomalies will be sent to the team for further investigation and feedback will be provided to us. This feedback needs to be incorporated into model training and prediction.
This blog post is focused on ranking the results of ML models which will help the downstream team to prioritize the investigation of the anomalies.
The current process looks like this.
Properties of the Ranking function
We want to achieve the following properties from the ranking function. These properties are more tailored to my use case but can be easily modified based on the problem and needs
- A score between 0 to 1. A score closer to 1 means a higher priority and vice versa.
- More weightage to the anomalies that occurs multiple times within a time frame.
- Scale the score of the anomaly if it was detected before by the ML model. Recently detected anomalies need to be weighted more compared to the anomaly that was detected before.
- Consider the consumer team’s feedback on already checked responses and incorporate that into your ML system.
Ranking Function
We will consider the ranking function in two parts:
- Baseline Ranking function: The baseline ranking function provides a score for the detected anomalies. There can be multiple approaches to it but will consider frequency-based approaches in this blog post to keep it simple and complete.
- Weighing Function for historical detections: The weighing function is a parameter that will include the historical score at a discounted factor.
Baseline Ranking function
-
Step function: The idea behind this approach is to use the frequency of occurrence of an anomaly as the ranking measure, i.e. if one anomaly appears multiple times in the result, then should be ranked higher than any anomaly which appears less number of times in the result. The score of the function needs to be in the range of
[0,1], we can divide the final score of anomaly bymax_valueso that score will lie in the desired range.Ranking_anomaly = F(frequency_anomaly, max_value) -
Sigmoid Function
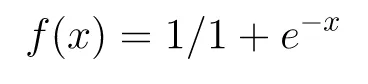
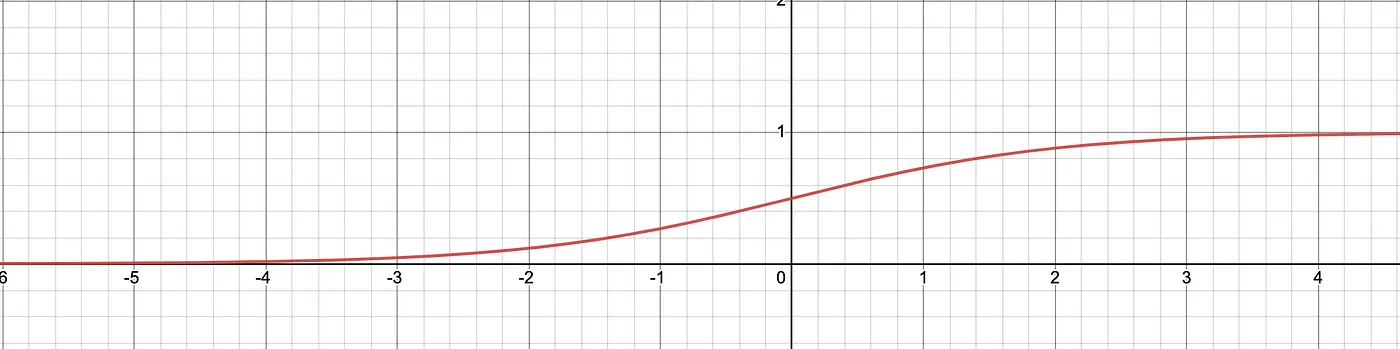 The sigmoid function is widely used in ML and the range of this function is already in
The sigmoid function is widely used in ML and the range of this function is already in [0,1]. This function has some properties that need to be modified to adapt it to our needs i.e
𝜎(x) → 0 as, x → ≤-4, we want the score to be as close to 0 when x → 0, therefore the range of this function needs to be shifted to the right by 4 units.𝜎(x) → 1 as, x → ≥ 3i.e. the value of x greater than 3 will be close to 1, we need to scale this function to reach a score close to 1 when let’s say we have at least 10 anomalies. i.e. function needs to be scaled by 0.7
Also in our case, if an anomaly is detected 10 times is as important as if it is detected 24 times in a day and still the score for the latter is greater than the former (although the magnitude is significantly less) and that is precisely what we want.
Now the equation becomes
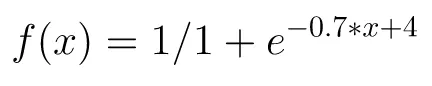
and the graph looks like this

Both of the above approaches work fine for most cases, but this one doesn’t account for the historical detections by the ML model for more than 1 day. To consider anomalies which are detected previously i.e. not on the same day, we can define some constant values for the historical detections. We want to give more weightage to anomalies that have been detected recently.
Weighing Function for historical detections
The idea here is to use a function that accounts for the score for the historical detections. We will use 𝛼 to denote this, basically in this case the whole equation will become something like this
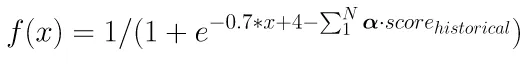
- Constant value for discounted historical score: Any value in the range
[0,1)will discount the score. This score can be adjusted based on the requirements and use case. There can be a different variation of this score, one variation is having separate weights for each day i.e. 0.8 for a 1-day difference, 0.3 for a 2-day difference, etc. Another variation can be defined by equal weight to each day and can be changed based on the needs and underlying problem to be solved. This can be easily implemented by maintaining a data structure that keeps the weights for each day and multiplying the score with this weight. - Time decay factor: This function will give more weight to recently detected anomalies and less weight to the anomalies detected earlier.
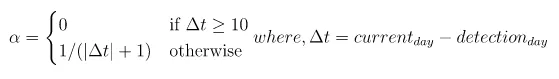
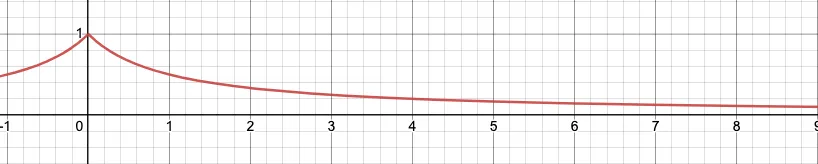
How long will it take to diminish the effect of an entry in the result?
This value of 𝛼 discounts scores at a rate of 0.5 i.e. for every day passed it changes the score to half. Small scores will vanish very quickly and larger scores will take a few days to come close to 0.
Implementation
This can be easily implemented in any database using SQL queries and can be scheduled as tasks. Anomaly detected are stored in a table with the timestamp which helps in tracking how many anomalies are generated in a particular hour or day. So finally the problem comes down to “how to write the above-explained ranking function?”.
The idea is to bring the previously ranked anomalies to one intermediate table and sum up the score of the current day with the historical score by joining the whole table. The historical score can be adjusted based on the flavor of the ranking function you want to use. Visually it can be understood as below figure
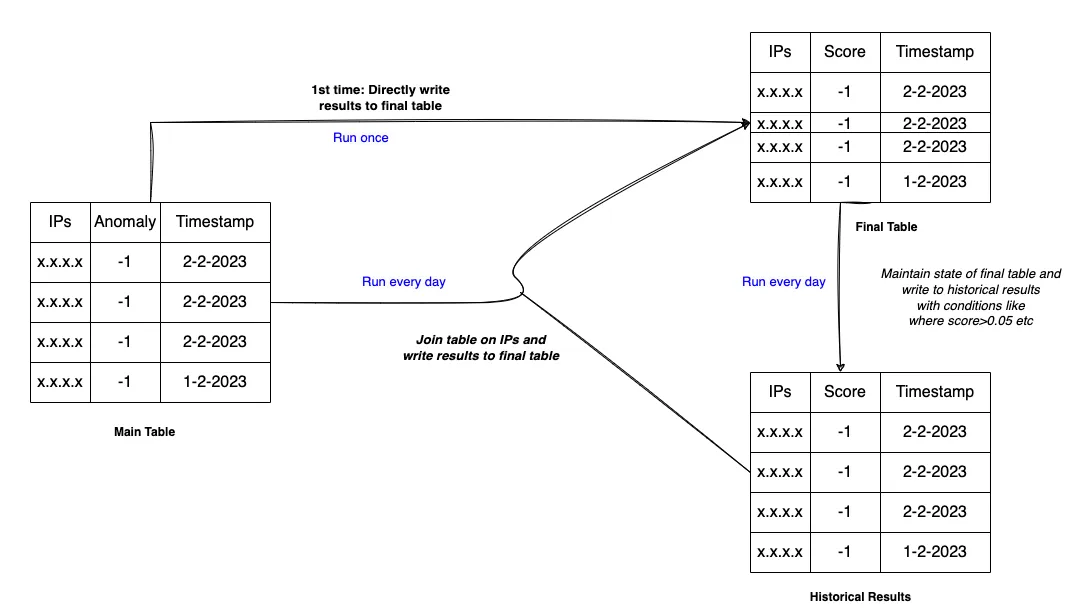
Each run can be scheduled as a task at a regular cadence based on the requirement. The consumer team can start looking at the anomalies and do the investigation based on the updated score from the historical data. Feedback from the team can be directly incorporated into the system either via a ranking function or can be used to filter data while training the ML model or at inference time. These decisions can be taken accordingly based on need and use case.
Please let me know if you like the post, or have some suggestions/concerns and feel free to reach out to me on LinkedIn.
References:
]]>